
In traditional SEO, crawl budget was a server-side metric. In Semantic SEO, it becomes a ranking catalyst.
Crawl Budget refers to the number of pages Googlebot is willing and able to crawl on your site within a given timeframe.
Every crawl consumes server bandwidth + machine resources. Every uncrawled page means:
- No indexing
- No ranking
- No semantic mapping
Thus, crawl budget is not a direct ranking factor—but a critical prerequisite for search visibility.
What is Crawl Budget?
Crawl Budget = Crawl Rate Limit + Crawl Demand
Crawl Rate Limit:
How many requests per second Googlebot can make without overwhelming your server
Crawl Demand:
How much Google wants to crawl your site, based on:
- Content freshness
- Page popularity
- Semantic relevance
- Internal linking structure
- Server health & speed
ALSO READ …
- What is cost of retrieval in SEO
- How do search engines work
- How does Google rank articles
- Google helpful content guidelines
- What is semantic search
Real-Time Data: Crawl Budget Monitoring in Google Search Console
From the video, the Search Console crawl stats show:
- Total downloaded size: 190MB (over 4 months)
- Total requests: ~8,000
- Response time: Fluctuates between 400ms – 800ms
- Indexing Rate: 77% HTTP 200 pages (✓)
- Smartphone crawler: 44% requests (✓)
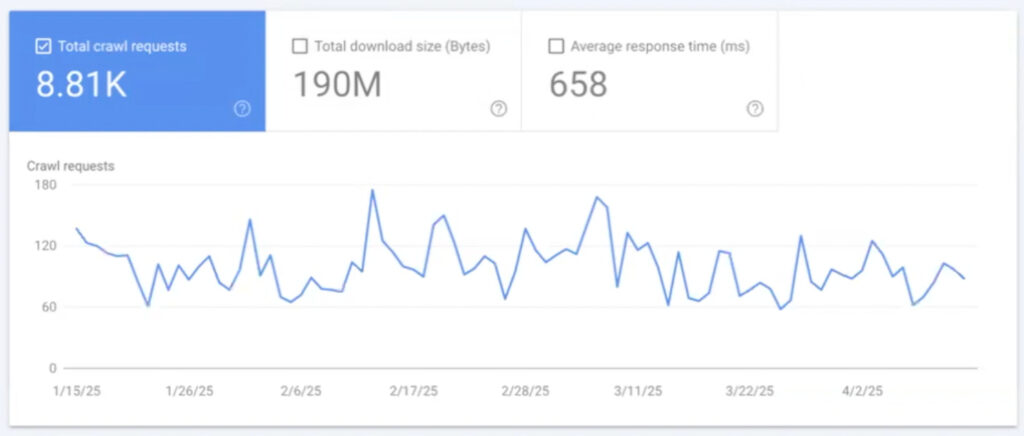
Key insights:
- More crawl requests = healthier indexation
- Lower response time = better crawl efficiency
- Spikes in requests often follow content updates or algorithmic changes
Why Crawl Budget is Essential for Semantic SEO
Crawl budget enables Semantic SEO because:
- Pages must be crawled before they can be parsed semantically
- Entities, schema, FAQ, topical relevance must be discovered through the crawl
- A stale or bloated site results in index decay, i.e. pages fall out of Google’s visible index
No crawl = no semantic extraction = no ranking context
How to Optimize Crawl Budget for Semantic SEO
1. Improve Crawl Efficiency (Reduce Cost Per Page)
- Use Robots.txt to block:
/wp-json/,/tag/,/feed/,/?s=
- Noindex Utility Pages:
- Privacy Policy, Terms, Search Results
- Set Canonical Tags to consolidate duplicates:
- Filtered URLs, UTM parameters, paginated series
2. Enhance Crawl Demand (Increase Desirability)
| Factor | Effect on Crawl Demand |
|---|---|
| Fresh content | Increases crawl frequency |
| Internal linking | Guides bots to critical pages |
| Structured data | Improves parsing speed |
| Topical clustering | Signals semantic focus |
| External backlinks | Increases URL discovery |
Crawl Budget vs Indexing vs Ranking: The Pipeline
- Crawl Budget unlocks crawl access
- Indexing stores the content
- Semantic Analysis identifies entities & intent
- Ranking Algorithm scores based on authority + relevance
Break the chain early, and ranking fails.
Technical Best Practices for Crawl Budget Optimization
A. Speed & Server Health
- Keep server response < 600ms
- Use fast hosting, SSD servers, optimized PHP/Node environments
- Eliminate 5xx server errors and slow TTFB (time to first byte)
B. Crawl Depth and Internal Linking
- Pages should be reachable within 2-3 clicks
- Avoid orphan pages (pages with no inbound links)
- Implement contextual in-body links, not just menu/footer links
C. XML Sitemap & Site Structure
- Submit an up-to-date sitemap
- Group pages by topical relevance
- Use flat architecture for shallow navigation
D. Remove or Consolidate:
- Outdated sales pages (e.g., Black Friday 2020)
- Duplicate product variants with canonicalization
- Mass-generated filter/tag/archive pages
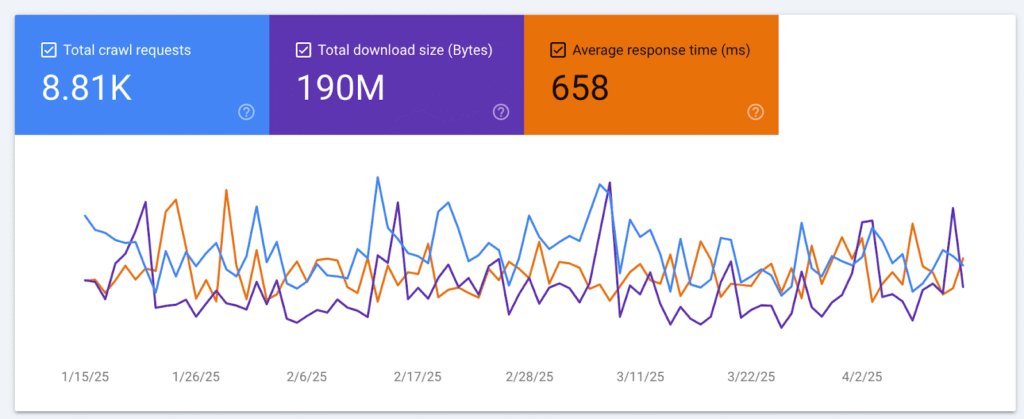
Crawl Budget Case Study Example (From Transcript)
- 190MB over 4 months = Healthy crawl volume
- Drop in requests post-March = Possible ranking loss or server slowdown
- Popular pages received higher frequency crawls (based on user behavior signals)
→ Crawl budget favors what’s popular and fresh
Crawl Budget & Semantic Signals: A Feedback Loop
- When Google crawls more often, it discovers:
- New entities
- Updated structured data
- Refreshed intent-based content
- This fuels Knowledge Graph inclusion and Featured Snippet eligibility
Semantic SEO feeds off recrawl frequency for context enrichment.
How to Monitor and Act:
| Tool | Insight |
|---|---|
| Google Search Console | Crawl stats, index status, errors |
| Log file analyzer | Real crawl paths & 404 tracking |
| Screaming Frog/Sitebulb | Crawl depth, orphan pages, speed |
| Robots.txt validator | Ensure critical pages are crawlable |
Checklist to Boost Crawl Budget ROI
| Task | Purpose |
|---|---|
Block low-value pages via robots.txt | Save crawl quota |
| Submit a focused XML sitemap | Guide bot to high-priority content |
| Improve page load speed (<600ms) | Enable faster crawling |
| Use internal linking for crawl paths | Boost discoverability |
| Add structured data (JSON-LD) | Improve semantic parsing |
| Use canonical tags for filters & variants | Prevent duplicate crawling |
| Update content regularly | Sustain high crawl demand |
| Reduce response time volatility | Ensure crawl reliability |
Final Insight: Crawl Budget is the Gatekeeper of Semantic Visibility
Crawl budget may not be glamorous, but in the semantic era, it’s foundational.
It decides what gets seen, when it gets seen, and how it gets understood.
Without crawl access, there’s no parsing.
Without parsing, there’s no semantic matching.
Without semantic relevance, there’s no organic ranking.
Next in Part 13: What is Structured Data? How It Impacts Semantic SEO and SERP Visibility
Disclaimer: This [embedded] video is recorded in Bengali Language. You can watch with auto-generated English Subtitle (CC) by YouTube. It may have some errors in words and spelling. We are not accountable for it.