
What Is TextRazor?
TextRazor is a semantic processing tool used to extract entities, topics, categories, and Wikipedia-backed IDs from raw text. It mimics how Google’s NLP layer might interpret and categorize your content.
Unlike keyword-based models, TextRazor builds a conceptual understanding by identifying entity-relation-attribute structures directly from body content.
Why Use TextRazor in Semantic SEO?
| Feature | SEO Benefit |
|---|---|
| Entity Linking | Maps to Wikipedia IDs (strong contextual signals) |
| Topic Categorization | Shows content topicality (like Google’s topic layers) |
| Confidence Scoring | Prioritizes strongest entities per document |
| Multi-source Analysis | Combine Wikipedia + Competitor Data for topical depth |
| Free API & UI | Accessible to all SEOs and content strategists |
Step-by-Step: Entity Extraction with TextRazor
1. Collect Raw Text
Sources to extract from:
- Wikipedia page of your main topic (e.g. Plumbing)
- Top-ranking competitors
- Internal service/blog content
2. Paste Content into TextRazor UI
Use TextRazor Demo
Click Analyze
ALSO READ …
- How Google detects entities using NLP
- How to extract entities using Google NLP tool
- How to help Google find entities on your content
- What is entity recognition in semantic
- What is structured data
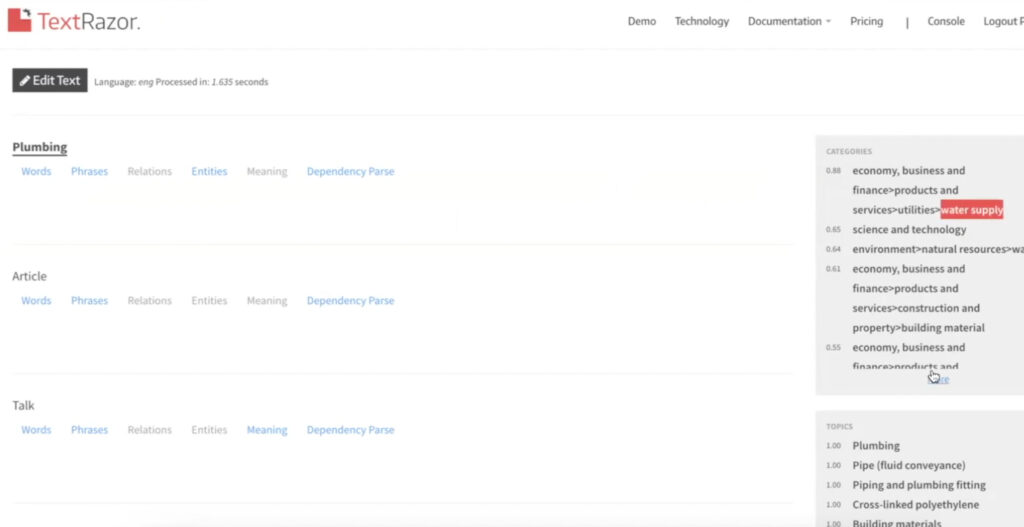
3. Entity Extraction Begins
You will get:
- List of entities (with Wikidata URLs)
- Entity Types (Person, Location, Consumer Good, etc.)
- Relevance Scores (Confidence and Salience)
- Disambiguated terms (connected to Knowledge Graph)
4. Build Your Entity Sheet (Recommended Columns)
| Entity | Type | Wikipedia Link | Relevance Score | Use In Content? (Y/N) |
|---|---|---|---|---|
| Plumbing | Thing | /wiki/Plumbing | 0.98 | Y |
| Pipe | Thing | /wiki/Pipe_(material) | 0.95 | Y |
| Water Heater | Consumer Good | /wiki/Water_heater | 0.92 | Y |
Combine With Google NLP Output
| NLP Tool Output | TextRazor Output |
|---|---|
| Entity Salience | Entity Confidence |
| Sentiment Score | Topic Category |
| ACRP Classification | Wikipedia ID |
Use both tools together to triangulate your entity list and improve semantic comprehensiveness.
Why Wikipedia-Linked Entities Matter
Google’s Knowledge Graph is heavily influenced by:
- Wikidata
- Wikipedia entity IDs
- Structured relationships between concepts
So if you include:
- Entities from Wikipedia
- With proper attribute-value pairs
- In contextually coherent sentences
Google can parse and index the content faster and with more confidence.
Conceptual Example: E-A-V with TextRazor Entities
Let’s assume we write about Plumbing:
| Entity | Attribute | Value |
|---|---|---|
| Water Heater | Energy Source | Electric |
| Pipe | Material | PVC |
| Plumber | Certification | Journeyman License |
| Sink | Installation Type | Undermount |
These E-A-V triples form the semantic backbone of a well-optimized content block.
Practical Application: Article Structuring
- Topical Sectioning using high-score entities
- Subheading Logic aligned with entity groups
- Attribute-value Injection per paragraph
- Internal Linking among pages that mention shared entities
- Schema Markup enriched with extracted entities (JSON-LD)
Warning: Post-Extraction Cleanup
- Not all terms are useful.
- Clean manually:
- Remove generic nouns (e.g. “illustration”, “talk”)
- Exclude brand mentions or UI terms (e.g. “logo”, “background”)
Tools Stack for Entity Extraction & Optimization
| Tool | Purpose |
|---|---|
| Google NLP | Entity salience, sentiment, category |
| TextRazor | Wikipedia ID, topic linkage |
| Wikipedia | Source corpus for seed entity mining |
| Competitor Sites | Contextual discovery of industry usage |
| Google Sheets | Manual deduplication + segmentation |
Advanced Use Case: Topical Authority via Entity Graph
- Extract 200+ entities from:
- Primary Topic
- Supporting Subtopics
- Competitor Pages
- Cluster them by:
- Type (Tool, Job Role, Process)
- Attribute Groups
- Search Intent
- Map them to URL structure + Internal Links
This builds semantic cohesion, which boosts crawl efficiency, entity salience, and ranking probability.
Coming in Part 20: How Google Detects Entities Using NLP – Part 20
Disclaimer: This [embedded] video is recorded in Bengali Language. You can watch with auto-generated English Subtitle (CC) by YouTube. It may have some errors in words and spelling. We are not accountable for it.