
Most SEO practitioners focus on content creation and backlinks, but few understand the systemic logic of how a search engine functions as an intelligent entity processor. Search engines like Google aren’t just listing documents anymore, they are interpreting meaning, evaluating context, and ranking content semantically.
In this part of the Semantic SEO series, we’ll talk about the search engine’s full pipeline from crawling to ranking with a focus on how semantic data flows through Google’s indexing architecture. This isn’t just technical SEO, it’s semantic system optimization.
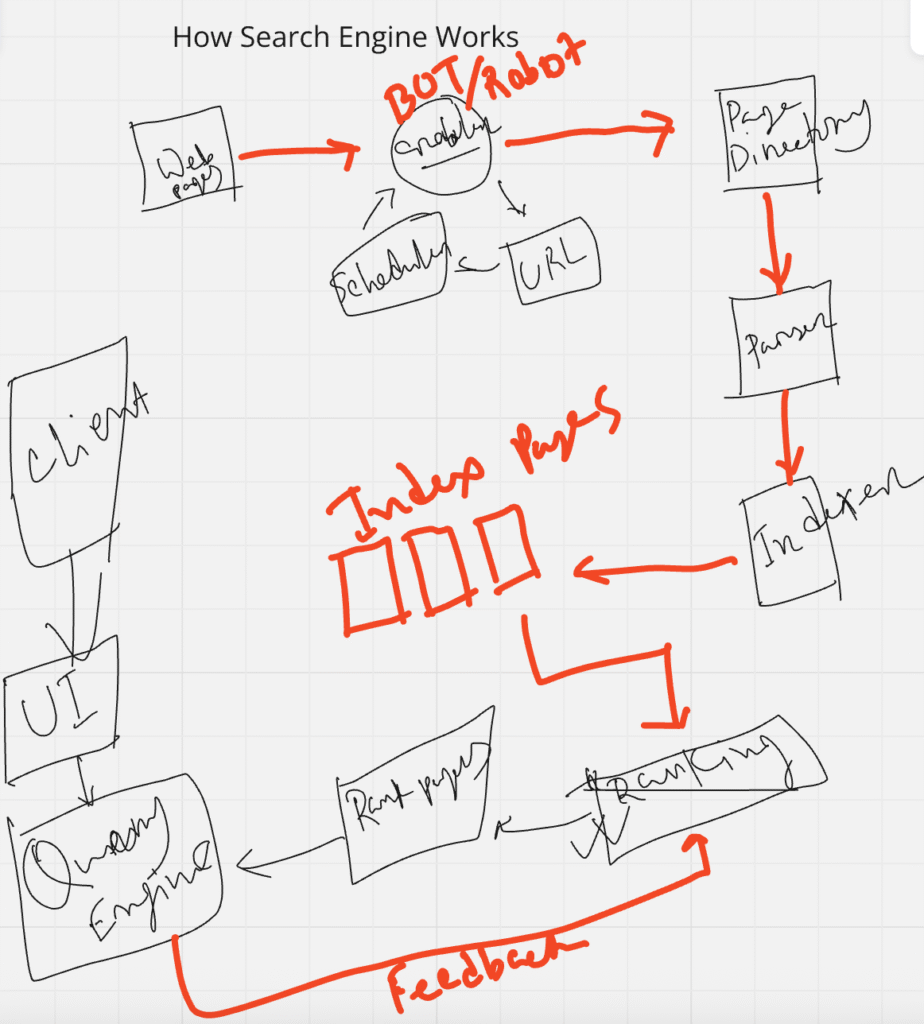
The Search Engine Pipeline (From Page to SERP)
Let’s break down the seven core stages in the search engine lifecycle:
- Web Page Creation
- Crawling
- Parsing
- Indexing
- Ranking
- User Interaction & Feedback
- Ranking Re-evaluation Based on Semantic Signals
Each stage adds another layer of meaning and structure, culminating in a semantic ranking decision.
Step 1: Web Page Creation – Where It All Starts
You write content, add metadata, maybe even apply schema markup.
But your page is still invisible to search engines—until it is discovered.
Step 2: Crawling – The Discovery Engine
Search engines deploy bots (aka spiders or crawlers) to fetch pages across the web.
- These bots follow URLs, sitemaps, and internal links
- A crawler scheduler determines the crawl frequency and priority
Semantic Insight:
Pages are crawled based on topical proximity and entity associations. A page linked semantically to a high-authority hub may be crawled more frequently.
ALSO READ …
- How does Google rank articles
- What is semantic search
- What is query semantics
- What is cost of retrieval in SEO
- Google helpful content guidelines
Step 3: Parsing – Breaking Down the Content
Once crawled, content is parsed to extract:
- Main content vs boilerplate
- HTML structure
- Embedded schema markup
- Named entities (e.g., “Apple iPhone 15” → Product, Brand)
At this stage, Google determines:
- Page type (e.g., blog post, product page)
- Topical focus
- Content depth
Semantic SEO Tip:
Use
mainEntity,about, andsameAsattributes in schema to guide the parser toward correct entity classification.
Step 4: Indexing – Semantic Inclusion in the Database
Parsed content moves into Google’s index, a massive graph database that stores:
- Nodes (Entities)
- Edges (Relationships)
- Properties (Attributes)
A page enters the index only if:
- It has meaningful, non-duplicate, value-driven content
- It passes quality thresholds (no spammy, thin, or irrelevant material)
You can verify indexing status using:
site:example.comsearch operator- Google Search Console (Coverage Report)
Crawled but Not Indexed
Occurs when content lacks entity clarity, topical coverage, or internal connectivity.
Step 5: Ranking – Entity-Based Relevance Scoring
After indexing, Google runs real-time ranking algorithms when a user performs a search.
The ranking system considers:
- Semantic relevance to the query
- Topical authority and domain trust
- User behavior signals (clicks, bounce rate, dwell time)
Semantic Ranking Is Not Keyword Matching
Google now uses:
- BERT / MUM / PaLM
- Entity co-occurrence graphs
- Intent vectors and topic clustering
“The page that best aligns with query intent + semantic context ranks highest.”
Step 6: User Feedback – Real-Time Refinement of Rankings
The search engine is not static. It adapts based on live user interaction signals:
- Click-Through Rate (CTR): Are users engaging?
- Bounce Rate: Are they leaving too quickly?
- Session Depth: Are they browsing multiple pages?
- Dwell Time: Are they consuming the content?
Example: If your page ranks for “digital marketing pizza,” gets impressions but no clicks, Google may demote it.
That’s feedback as a ranking signal.
Step 7: Dynamic Re-Ranking & Re-Crawling
Pages don’t remain indexed or ranked forever. They are:
- Re-crawled
- Re-evaluated
- Removed or demoted if signals weaken
Factors triggering re-crawling:
- New backlinks
- Content updates
- Internal link restructuring
- Schema markup enhancement
Keep content fresh, contextual, and connected to preserve ranking longevity.
Bonus: Semantic Signals That Influence Crawling & Indexing
| Signal | Impact on Indexing/Ranking |
|---|---|
| Schema Markup | Enhances entity clarity for parsers |
| Internal Links | Strengthens semantic connections |
| External References | Boosts entity trust & verifiability |
| Page Freshness | Improves crawl rate & topical relevance |
| Entity Density | Correlates with salience in NLP analysis |
| Topic Consistency | Reinforces domain authority |
Visualization: How Google Processes a Page
User → Enters Query → Search Engine Interface
↓
Query → NLP → Entity Extraction → Intent Understanding
↓
Index → Semantic Matching (Entities + Context)
↓
Ranking Layer → Personalized Factors + Real-Time Feedback
↓
SERP → Result Display → Click + Dwell Time → Feedback Loop
Conclusion: The Search Engine Is a Semantic Engine
Understanding how search engines work is no longer just technical—it’s semantic.
Every stage from crawling to ranking is optimized around:
- Meaning over keywords
- Entities over strings
- Context over density
To win SEO in 2025 and beyond, your content must:
- Feed structured, meaningful data to crawlers
- Be semantically rich, topically deep, and entity-connected
- Align with how Google interprets, stores, and retrieves content
Coming in Part 8: How Does Google Rank Articles? Understanding Google’s Semantic Ranking Factors
Disclaimer: This [embedded] video is recorded in Bengali Language. You can watch with auto-generated English Subtitle (CC) by YouTube. It may have some errors in words and spelling. We are not accountable for it.