
Google doesn’t rank keywords. Google ranks entities.
And it understands entities by transforming your unstructured content into structured knowledge via Natural Language Processing (NLP) and contextual embeddings.
So, instead of seeing a “keyword,” Google sees a structured triple:
Entity: Washington D.C.
Attribute: is a
Value: Capital of the USANLP and Google’s 4-Phase Entity Detection Pipeline
Google doesn’t rely on exact-match keywords—it builds contextual meaning from text using these four phases:
Phase 1: Preprocessing (Understanding Raw Text)
The first step in entity detection involves breaking down text into structured information through linguistic analysis. The ‘preprocessing’ step. This prepares raw text for data analysis.
This preprocessing phase includes:
Example Sentence:
Washington is famous for its rich history and landmarks.
Tourists often visit Washington to see the White House, museums, and monuments. While some people think of Washington as a state on the West Coast, others know it as the capital of the United States. Both places attract millions of visitors every year.
1.1. Tokenization: Dividing text into tokens (words, sentences, or subwords).
👉[‘Washington’, ‘is’, ‘famous’, ‘for’, ‘its’, ‘rich’, ‘history’, ‘and’, ‘landmarks’]
1.2. Stopword Removal: Removing common but non-informative words (e.g., “and,” “the”).
👉 [‘Washington’, ‘famous’, ‘rich’, ‘history’, ‘landmarks’]
1.3. Stemming: Reducing words to their root forms using rules (e.g., “running” → “run”).
👉 [‘washington’, ‘famou’, ‘rich’, ‘histori’, ‘landmark’]
1.4. Lemmatization: Converting words to their base forms based on context (e.g., “better” → “good”).
👉 [‘Washington’, ‘famous’, ‘rich’, ‘history’, ‘landmark’]
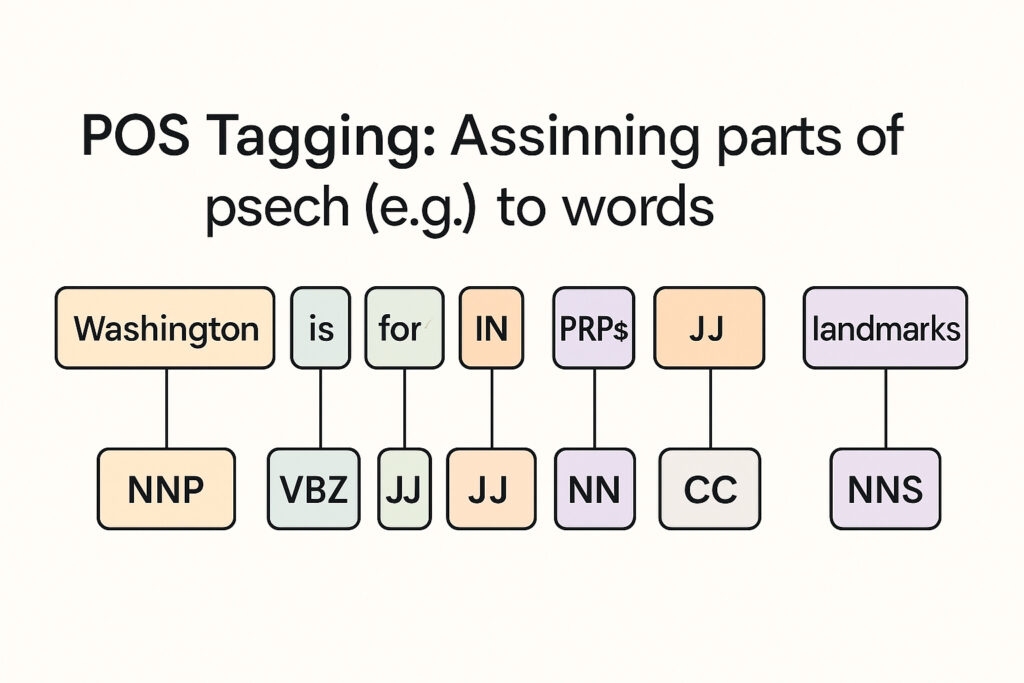
1.5. POS Tagging: Assigning parts of speech (e.g., noun, verb) to words.
👉 [(‘Washington’, NNP), (‘is’, VBZ), (‘famous’, JJ), (‘for’, IN), (‘its’, PRP$), (‘rich’, JJ), (‘history’, NN), (‘and’, CC), (‘landmarks’, NNS)]
| Word | Part of Speech (POS Tag) | Meaning |
|---|---|---|
| Washington | NNP (Proper Noun, Singular) | A specific name (city/state/person) |
| is | VBZ (Verb, 3rd Person Singular Present) | Linking verb “to be” |
| famous | JJ (Adjective) | Describes “Washington” |
| for | IN (Preposition) | Shows relation or purpose |
| its | PRP$ (Possessive Pronoun) | Shows possession |
| rich | JJ (Adjective) | Describes “history” |
| history | NN (Noun, Singular) | Thing being possessed |
| and | CC (Coordinating Conjunction) | Connects words/phrases |
| landmarks | NNS (Noun, Plural) | Multiple things being listed |
1.6. Text Normalization: Lowercasing text, removing punctuation, or correcting misspellings.
👉 ‘washington is famous for its rich history and landmarks’
👉 (Also could remove punctuation, but there’s none here)
This foundational analysis creates the structured information necessary for more sophisticated entity detection in subsequent steps.
Purpose: Turn messy human language into machine-readable format
Also Read ..
See how Google processes unstructured content
Learn about tools like Google NLP and TextRazor
Phase 2: Feature Extraction (Vectorization)
Text is converted into numerical formats:
Example:
Washington is famous for its rich history and landmarks.
2.1. Bag-of-Words (BoW): Represents text as a sparse matrix of word counts or frequencies.
Simply, BoW is: Just counts how many times it appears
What it does:
Converts text into a sparse matrix where each cell represents the count of a word in the sentence.
Example:
| Word | Count |
|---|---|
| washington | 1 |
| is | 1 |
| famous | 1 |
| for | 1 |
| its | 1 |
| rich | 1 |
| history | 1 |
| and | 1 |
| landmarks | 1 |
Explanation:
Each word is treated as a distinct feature. It doesn’t understand the meaning — it’s just counting. Washington gets a value of 1.
2.2. TF-IDF: A weighted representation that balances term frequency (TF) with inverse document frequency (IDF) to downweight common words.
Simply TF-IDF is: Weights it based on rarity in a larger corpus
What it does:
Adjusts the weight of each word by how common it is across multiple documents — frequent words in one document but rare across others get higher importance.
Example (hypothetical values):
| Word | TF-IDF Value |
|---|---|
| washington | 0.8 |
| is | 0.1 |
| famous | 0.6 |
| for | 0.1 |
| its | 0.1 |
| rich | 0.5 |
| history | 0.7 |
| and | 0.1 |
| landmarks | 0.6 |
Explanation:
Washington has a higher value because it’s likely a unique or less frequent word in a larger corpus, unlike is, and, for, etc.
2.3. Word Embeddings: Dense vector representations of words that capture semantic relationships (e.g., Word2Vec, GloVe, FastText).
Simply Word Embedding is: Places it semantically near similar words
What it does:
Represents each word as a dense vector capturing its meaning relative to other words.
Example (simplified vectors)
| Word | Embedding (3D example) |
|---|---|
| washington | [0.81, 0.42, 0.55] |
| famous | [0.60, 0.70, 0.20] |
| history | [0.72, 0.30, 0.66] |
| landmarks | [0.68, 0.45, 0.61] |
Explanation:
Here, Washington might be close in vector space to D.C., Seattle, or state, meaning the model understands its relationship to other words.
2.4. Contextual Embeddings: Context-sensitive word representations derived from transformers like BERT, MUM or GPT.
Simply, Contextual Embeddings is: Understands meaning based on sentence context
What it does:
Assigns vector representations based on context, so the same word gets different vectors in different sentences.
Example:
- In “Washington is famous for its landmarks”
→ Washington → [0.85, 0.23, 0.67] - In “George Washington was the first president”
→ Washington → [0.65, 0.72, 0.55]
Explanation:
Unlike Word2Vec or BoW, contextual embeddings know if we’re talking about the city or the person, by adjusting the vector based on nearby words.
This step builds the contextual fingerprint of every word or phrase.
Phase 3: Model Building (Pattern Recognition)
Multiple AI models process the vectorized input:
Different algorithms will be built using a variety of approaches to analyse the numerical data collected in step 2.
Example:
Washington is famous for its rich history and landmarks.
3.1. Rule-Based Models: Use rules or patterns (e.g., grammar rules) to analyse text.
What it does:
Uses manually defined grammar or pattern rules to detect entities or facts.
Example:
A rule like:
- If a proper noun (NNP) appears at the start of a sentence, treat it as a potential named entity.
In our text:
- Washington is tagged as NNP → Rule triggers → classified as a Named Entity
3.2. Statistical Models: Use probabilities to predict patterns in language (e.g., Hidden Markov Models).
What it does:
Uses probabilities based on training data to predict patterns (like part-of-speech sequences or named entities).
Example:
Using a Hidden Markov Model (HMM), the probability of Washington being a proper noun given its position and surrounding words is calculated.
In our text:
- P(NNP | “Washington”) is very high
- P(JJ | “famous”) is also high
- Sequence pattern: NNP → VBZ → JJ
3.3. Machine Learning Models: Use algorithms like Naïve Bayes or SVM to classify or group text.
What it does:
Uses labeled examples (supervised learning) to classify or group text.
Example (Naïve Bayes or SVM):
We train the model on sentences labeled with entities and their types.
In our text:
- The model predicts Washington as a Location based on features like:
- Position in sentence
- Word shape (capitalized)
- Neighboring words (like is, famous, history)
Explanation:
It uses patterns from training data to make predictions — fast and works well with limited data.
3.4. Deep Learning Models: Use neural networks to understand language:
RNNs and LSTMs: Handle sequences, like sentences.
🌀 RNNs & LSTMs (Remembers preceding words to interpret meaning)
What it does:
Processes sequences word-by-word, remembering previous words to understand context.
In our text:
- By reading:
Washington → is → famous → for… - It retains context so by the time it reaches landmarks, it understands Washington is a place.
Explanation:
Sequential memory makes it context-aware — but struggles with long sentences.
CNNs: Extract important features from text.
CNNs – Detects local word patterns around it
What it does:
Looks at fixed-sized word windows to pick out important patterns.
In our text:
- A 3-word window might pick out phrases like:
- Washington is famous
- famous for its
- The model detects patterns like proper noun + verb + adjective
Explanation:
Captures important local patterns — useful for text classification and entity detection.
Transformers: Powerful models like BERT, MUM and GPT that understand context in sentences.
It Understands full-sentence context to infer meaning
What it does:
Uses self-attention to understand relationships between all words in a sentence at once.
In our text:
- It learns that Washington relates to landmarks, history, famous
- If context changes, it would know whether Washington is a state, city, or person
Explanation:
Most powerful, context-sensitive, bidirectional (like BERT), or autoregressive (like GPT), making sense of the full sentence before making a decision.
| Model Type | Function |
|---|---|
| Rule-Based Models | Uses grammar rules to classify entities |
| Statistical Models | Predicts probability of word categories (Hidden Markov) |
| Machine Learning | Uses trained data to detect patterns (Naive Bayes, CRF) |
| Deep Learning | BERT, Transformer-based, understands deep contextual meaning |
Example: So, The term “Washington” is disambiguated by nearby terms like White House or landmark to classify it as Washington, D.C., not the U.S. state or George Washington.
Phase 4: Inference. Where we find real meaning through entities
What Happens at This Phase
- Your page’s text has already gone through:
- Preprocessing (cleaning, tagging)
- Feature extraction (turning words into numbers/vectors)
- Model building (algorithms analyze those numbers)
Now — in inference, the system uses those processed features to:
- Run Named Entity Recognition (NER)
→ Detect things like Washington → is this a person? city? state? - Connect it to the Knowledge Graph
→ “Washington” → [Washington, D.C.] or [George Washington] or [Washington State] etc.
If it finds a match, it links the mention in your content to the relevant real-world entity.
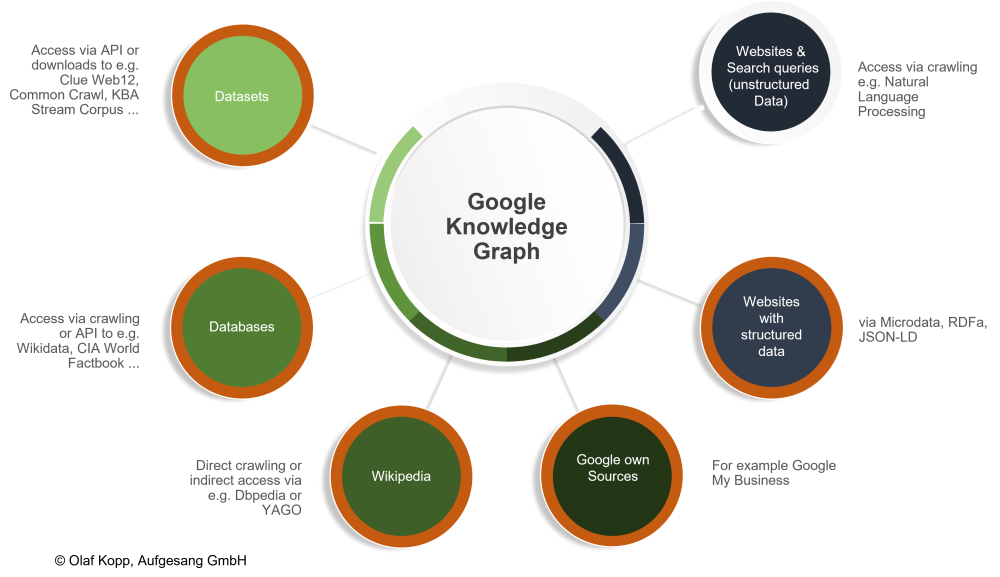
How the Knowledge Graph Fits In
The Knowledge Graph is like a huge, structured network of facts Google already knows.
Example:
- Washington might be linked in the graph to:
- Category: City
- Country: USA
- Landmarks: White House, National Mall
When your page mentions Washington, Google tries to infer which “Washington” you mean, based on context, related words (like landmarks, history), and even data from other pages on your site.
So, your content doesn’t exist alone on the web — or even on your own site.
When Google analyzes a page:
- It considers other pages it already knows about — from both your site and other sites.
- These linked, indexed pages form a network — so entities in one page can provide clues for understanding entities in another.
Example: If another page on your site says:
Washington is the capital of the United States.
Then when your new page says:
Washington is famous for its landmarks.
Google connects the dots:
“Ah — they mean Washington, D.C. again.”
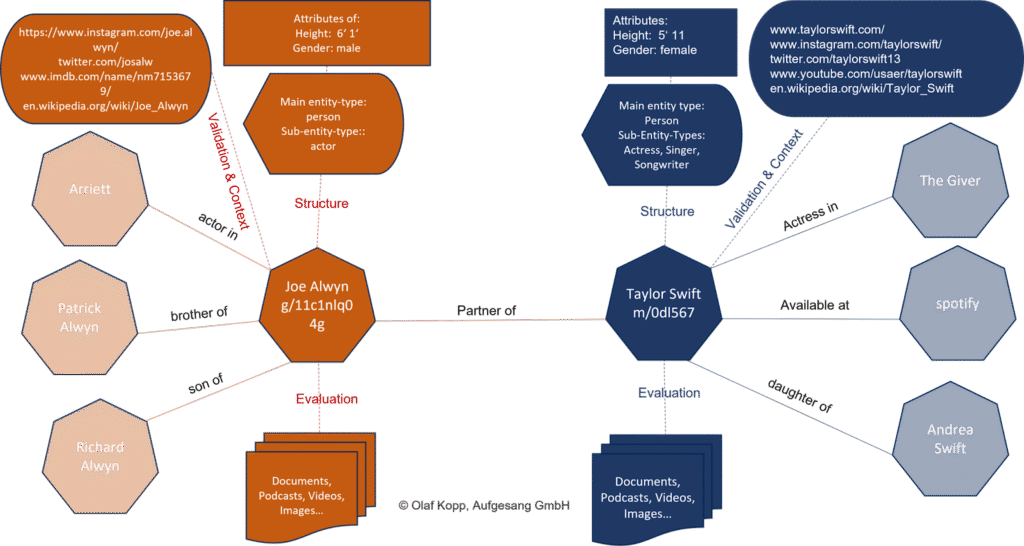
So, Once the model classifies the entity, it links it to a Knowledge Graph node:
| Detected Term | Linked Entity | Source |
|---|---|---|
| Washington | Washington, D.C. | Wikidata |
| Taylor Swift | Person > Music Artist | Google KG + Wikipedia |
| Tesla | Organization > Brand | Freebase (now retired) |
Final entity is stored in Google’s Knowledge Vault, connecting relationships, attributes, synonyms, and topical relevance.
NLP in Action: Washington Example
| Sentence | Entity Detected | Disambiguation Logic |
|---|---|---|
| “Washington is famous for landmarks” | Washington, D.C. | Nearby words: “White House”, “monuments”, etc. |
| “George Washington led the revolution” | George Washington | Preceding word: “George” + verb pattern |
| “Visit Washington state this spring” | Washington (State) | Context: “state”, location signal |
Google’s context-aware NLP resolves ambiguous terms by analyzing semantic roles and word position patterns.
Theoretical Foundations Behind This
Google has filed patents to explain these systems:
- Ranking Search Results Based on Entity Metrics (2012)
- Using Entity References in Unstructured Data
- Identifying Topical Entities
These patents describe how entity-centric ranking systems prioritize structured information and contextual relevance over keyword density.
How This Powers Semantic SEO
| NLP Stage | SEO Application |
|---|---|
| Tokenization | Prepares content for indexing |
| Vector Embedding | Enhances topical clustering and keyword relevance |
| POS Tagging | Enables better title/entity detection |
| Knowledge Mapping | Links content to Google’s Knowledge Graph |
| Context Embedding | Powers BERT and MUM — fuels passage ranking, featured snippets |
Practical Implications for Content Creators
Optimize for Entity Recognition
- Use explicit entity mentions (e.g., “Elon Musk, the CEO of Tesla”)
- Include disambiguating context
- Surround entities with relevant attributes and values
- Leverage structured data for markup (JSON-LD preferred)
Build Entity-Rich Content Architecture
- Use Entity-Attribute-Value (EAV) frameworks
- Add Wikipedia-linked terms in key paragraphs
- Align internal links around topical entities
- Develop Topical Maps: group entities into clusters (Person → Company → Product)
Use NLP Tools to Analyze Your Content
| Tool | Use Case |
|---|---|
| Google NLP | Entity + Salience + Sentiment Analysis |
| TextRazor | Wikipedia-based entity linking |
| InLinks | Internal linking and topic structuring |
| On-Page.ai | Entity optimization + SERP analysis |
Summary: NLP is the Engine of Google’s Entity Understanding
Google no longer “reads” content like a search engine from 2010. It understands content like a semantic web. Using:
- Tokenization
- Embeddings
- Deep learning models (BERT, MUM)
- Knowledge Graph linking
…it maps every phrase, every topic, and every brand into a network of meaning.
Example Entity Structure in a Knowledge Graph
https://patents.google.com/patent/US10235423B2/en
https://patents.google.com/patent/US20150278366
https://patents.google.com/patent/US20160371385
In the next part 21: How to Help Google Find Entities on Your Content Page
Disclaimer: This [embedded] video is recorded in Bengali Language. You can watch with auto-generated English Subtitle (CC) by YouTube. It may have some errors in words and spelling. We are not accountable for it.